
Apreciado trader,
Como sabrás, el backtesting es una parte fundamental en el desarrollo de estrategias de trading. Por esta razón, he decidido crear una serie de artículos donde voy a tratar todos los puntos necesarios sobre como hacer backtesting de una estrategia de trading algorítmico correctamente.
Mi objetivo con este artículo es que tengas una guía práctica que te permita realizar backtest en los que puedas confiar para tomar tus propias decisiones con las mayores garantías posibles.
Para que todo este asunto no quede solamente en la teoría, voy a utilizar el ejemplo real de la estrategia KLV de nuestra firma KomaLogic. Creo que utilizar ejemplos prácticos de un caso de uso es la mejor manera de acompañar los conceptos teóricos que explicaré. Al fin y al cabo, son todos los pasos que nos han servido a nosotros para crear una estrategia real que cuenta con inversión.
Organización del artículo
Éste es el primero de una serie de artículos sobre cómo hacer backtesting de una estrategia de trading algorítmico correctamente. El objetivo de estos artículos será el de describir todos los procesos, prácticas y medidas a tomar para que aprendas cómo hacer backtesting de la manera más fidedigna posible.
En este primer artículo me centraré básicamente en cómo limpiar datos históricos y la importancia que tiene dicha limpieza en la validez final del proceso de backtesting. Como es un tema de por sí denso, voy a acompañarlo constantemente de ejemplos e imágenes que ilustran los conceptos de manera fácil para que se entiendan rápidamente.
Durante toda esta serie de artículos voy a dar por hecho también que la estrategia que vamos a backtestear está codificada en un algoritmo.
¿Qué es el Backtesting?
Antes de entrar en materia y poder explicar cómo hacer backtesting de una estrategia de trading correctamente, conviene tener claro qué es un backtest y para qué sirve. Voy a ser lo más claro y conciso que pueda:
Un backtest es el proceso de poner a prueba una estrategia de trading utilizando datos históricos y sirve para evaluar cómo se hubiera comportando dicha estrategia en el pasado.
Es decir, utilizamos el backtesting para ver cómo se hubiera comportado una estrategia de trading durante los últimos 10 años (por ejemplo) y sacamos conclusiones de ello.
Suena sencillo, y en esencia lo es. Sin embargo, hay variables que se deben tener en cuenta para poder garantizar la validez de este proceso, dado que hay una multitud de errores en los que podríamos caer sin darnos cuenta que arruinarían la validez estadística de dicha prueba y de las conclusiones que podríamos sacar de ella.
Así que ahora sí, manos a la obra. Lo primero que vamos a necesitar será una plataforma que disponga de un buen motor de backtest.

Plataformas de Backtesting
La primera cuestión que debes tener en cuenta a la hora de realizar un backtest es conocer cuáles son las mejores plataformas para hacer backtesting y cómo funciona su motor de backtest. Normalmente, la opción más sencilla es utilizar el que viene por defecto en la plataforma de trading que estés utilizando. Cada plataforma tiene también su propio lenguaje de programación con el que deberás haber creado la estrategia, de manera que también determinará en gran medida toda tu infraestructura tecnológica. A continuación, te comparto los casos más típicos:
- MetaTrader 4: MQL4
- MetaTrader 5: MQL5
- CTrader: C#
- TradeStation: EasyLanguage
- MultiCharts: C++, C#, VB.NET, EasyLanguage
- NinjaTrader: NinjaScript (una extensión de C#)
- ProRealTime: ProBuilder
Evidentemente, también existe la opción de crear un motor personalizado si las plataformas anteriores no pueden cumplir con tus necesidades. Si este fuera el caso, te comparto también algunos buenos frameworks para crear tu propio software de backtesting en Python:
Conocer bien el motor de backtest es importante porque cada motor tiene sus propias características y las debes tener en cuenta para que el resultado del backtest emule lo mejor posible el comportamiento que hubiera tenido la estrategia en la realidad.
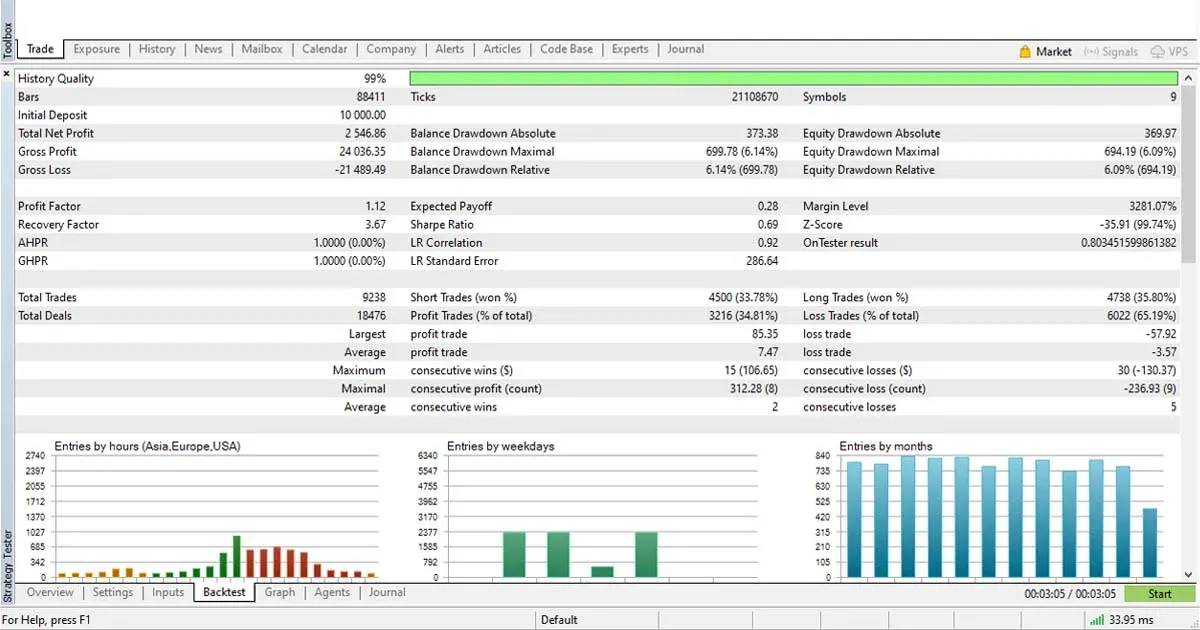
Para ponerte un ejemplo, el motor de backtest de la plataforma MT5 procesa absolutamente todos los ticks que tiene tu dataset, algo que no tendría por qué ocurrir durante el trading a tiempo real. Este ejemplo en concreto puede no parecer muy importante, y en algunos casos es probable que tampoco signifique ninguna diferencia notable. Sin embargo, si quieres que tus backtest sean lo más precisos posible, debes tener en cuenta este tipo de detalles.
Siguiendo con este ejemplo de MT5, fíjate en lo que dice la documentación oficial de la plataforma al respecto:
El evento NewTick se genera con la llegada de nuevas cotizaciones y se procesa por la función OnTick() de los Asesores Expertos adjuntos. Si con la llegada de nuevas cotizaciones la función OnTick está en ejecución para las cotizaciones anteriores, en este caso el Asesor Experto ignorará la cotización que ha llegado, porque el evento correspondiente no va a ponerse en la cola de eventos del Asesor Experto.
Todas las cotizaciones que llegan durante la ejecución del programa se ignoran hasta que se finalice la ejecución correspondiente de la función OnTick(). Después de eso, la función se iniciará sólo después de que se reciba una cotización nueva.
Fuente: Documentación MT5
Como ves, durante un backtest, el funcionamiento no sería exactamente el mismo que lo que ocurriría en tiempo real. Y a situaciones como esta son a las que me refería. En este caso, tendrías que introducir en tu estrategia un código de control de ejecución que garantizara que la manera de procesar los ticks a tiempo real y en el backtest fueran exactamente las mismas.
Este es un problema fácil de solucionar: simplemente ejecuta tu código en el primer tick de cada vela. Sin embargo, esto sólo tiene sentido si trabajas con velas japonesas (o cualquier otra forma de agregación por tiempo). Si trabajas con datos tick a tick, este problema se vuelve más complejo de solucionar: debes estimar el tiempo de ejecución de tu código para cada nuevo tick y verificar si a la hora de llegada de cada nueva cotización, tu programa ya se habría ejecutado y estaría libre para volver a hacerlo.
Por ahora, doy por hecho que ya tienes tu motor de backtest elegido y estudiado, así como tu estrategia programada en el lenguaje que tu plataforma necesita. Pasemos entonces al siguiente aspecto a tener en cuenta: los datos históricos.
Datos Históricos
Para realizar un backtest correctamente es esencial disponer de los datos históricos de los activos sobre los que quieres evaluar tu estrategia. Tal y como comentaba antes, el objetivo del backtest es el de poder evaluar los resultados de una estrategia en el pasado, por lo que disponer de datos históricos de calidad es de vital importancia. Nótese el énfasis en la palabra calidad. Los datos históricos son la materia prima del backtest, de manera que datos con errores nos llevarán a backtests con errores y, de manera irremediable, llegaremos también a conclusiones con errores. Creo que ya entiendes por dónde voy.
Los datos históricos son la materia prima del backtest. Es imprescindible que sean datos de calidad como los que ofrece la plataforma de Quantdle (los que usamos en KomaLogic).
Primero voy a enseñarte, con ejemplos, a qué me refiero cuando hablo de datos de calidad y más adelante te explicaré cómo deberías procesarlos para asegurarte de que los datos puedan ser utilizados en un backtest.
Datos de Calidad
Cuando hablo de datos históricos de calidad, me refiero a datos precisos y fidedignos, que representen con la máxima veracidad lo que realmente ocurrió y que estén libres de errores. Y quizás podrías pensar: ¿es que acaso los datos históricos que hay disponibles tienen errores? Yo mismo cometí el error de creer que los datos históricos que podía obtener de una institución o un broker ya serían de calidad, pero me llevé una agradable sorpresa (nótese la ironía) al descubrir que no podía estar más equivocado. De aquí surgió un primer principio:
Revisa y analiza siempre los datos históricos, independientemente de lo reputada que pueda ser su fuente, antes de utilizarlos en un backtest.
De manera que no basta con descargar los datos, sino que hay que revisarlos y, quizás, transformarlos. No es lo mismo descargar datos tick a tick que descargar datos con temporalidades ya definidas como podrían ser los precios de cierre de cada hora o de cada día.
Si quieres ver cómo descargar los datos tick de Darwinex, te recomiendo que visites este artículo del blog de nuestro amigo Iván García.
Y por si quieres ahorrarte todo este tedioso proceso, hemos diseñado Quantdle, una herramienta para obtener los datos ya procesados y limpios para tus backtesting en dos clicks.
En KomaLogic descargamos siempre datos tick a tick, los procesamos y los convertimos a datos OHLC (Open, High, Low, Close) con periodicidad de un minuto. Para ello, seguimos los pasos que veremos a continuación.
Ausencia de valores NaN
La primera acción que realizamos cuando hemos descargado los datos tick es comprobar que no tienen valores NaN (Not a Number), es decir, valores nulos. Si, por ejemplo, estamos interesados en el precio de cierre diario de un activo y justamente para el día 12 de mayo el valor de cierre es NaN, significaría que ese dato en concreto no existe (por multitud de razones, una de ellas pudiendo ser que nuestro dataset contiene errores) y tenemos que decidir qué hacer con él. Generalmente existen dos opciones:
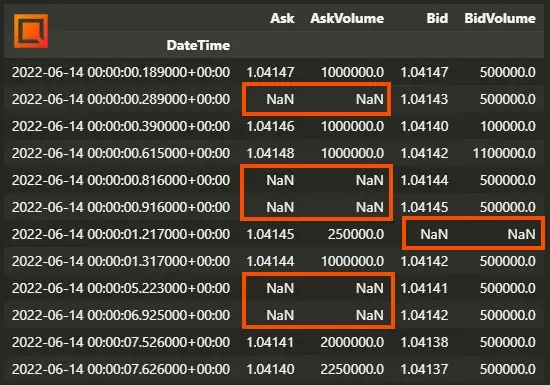
La primera y más sencilla: eliminar la fila entera. Esto significa que si para el día 01 de marzo tenemos que el máximo del día es un NaN, pues simplemente eliminamos todos los datos del día 01 de marzo y no los tenemos en cuenta durante el backtest. Esta opción puede ser de utilidad con datos OHLC (datos de velas japonesas); sin embargo, podría traernos serios problemas en caso de datos tick. Veámos el por qué.
En el caso de la imagen anterior (datos tick), sería un error eliminar todas las filas que contienen un NaN directamente. Si hacemos un estudio más detallado, nos daremos cuenta de que muchas de esas filas contienen un NaN en el Ask pero no en el Bid, y viceversa. Eso significa que justamente en ese momento en el tiempo hubo un nuevo precio Bid pero ningún precio Ask, algo que es completamente normal.
En estos casos, para no perder datos, podemos simplemente propagar los valores anteriores con una instrucción del estilo data.fillna(method='ffill') en Python. Fíjate como los valores que antes eran NaN ahora tienen el mismo valor del dato anterior, lo que básicamente significa que el precio no ha cambiado entre esos dos instantes de tiempo.
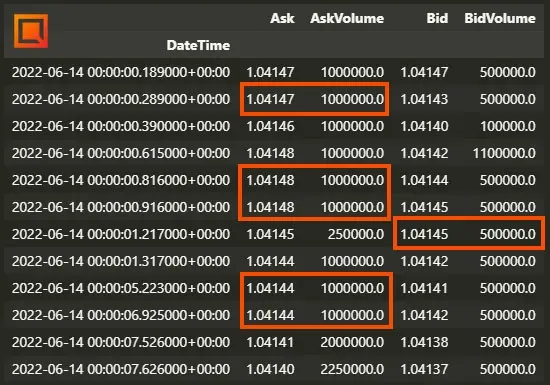
Sin embargo, en este caso estaríamos falseando el volumen asociado a ese nivel de precio, ya que en ese lapso de tiempo no se negoció realmente ningún contrato en el Bid o Ask. Si te fijas, con esa instrucción hemos propagado todos los valores para rellenar los campos NaN, con lo que estaríamos introduciendo errores en los datos diciendo que se negoció el mismo volumen en cada precio propagado que en el precio anterior. Para solucionarlo, lo que podemos hacer primero es simplemente colocar un valor de 0 en todas las columnas AskVolume y BidVolume que tuvieran un valor NaN en su Ask o Bid.
Apunte importante: Técnicamente, un valor de 0 volumen significa que no se ha negociado ningún contrato en ese precio y, por ende, ese precio no debería existir (y alguna plataforma de Backtesting podría arrojarnos un error debido a eso).
Si más tarde hacemos un resampling de los datos tick a OHLC este problema ya no nos preocuparía, pero si en tu plataforma necesitas cargar datos tick, lo que podrías hacer es simplemente colocar un valor de 1 en lugar de 0. Con esto no tendrías un resultado perfecto, pero un valor de 1 es despreciable al lado de los otros valores de volumen que están 6 ordenes de magnitud por encima (en este ejemplo). En cualquier caso, la decisión final queda en tus manos según el activo que estés operando y tus necesidades. En nuestro ejemplo, el resultado de aplicarlo en el set de datos anterior sería el siguiente:
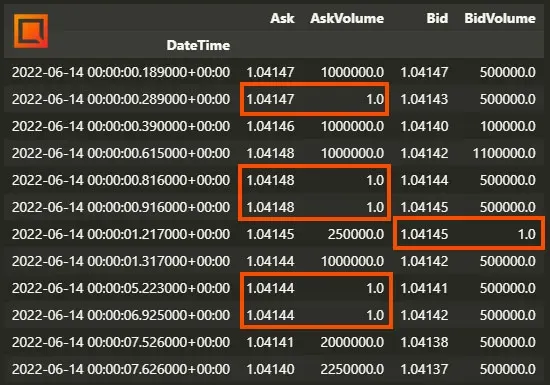
La segunda es intentar inferir el dato. Esto se puede hacer de varias maneras:
-
La primera es utilizar el número anterior, lo que se traduciría en que los precios se mantienen exactamente iguales en ambos casos (como en el ejemplo que acabamos de ver). Esto es más sencillo de hacer cuando estamos procesando datos tick, ya que en caso de OHLC (datos de velas japonesas), para poder utilizar el dato anterior tendrás que cumplir con ciertos requisitos. Por ejemplo, si te falta el dato de apertura, puede ser una buena opción utilizar el precio de cierre anterior. Pero quizás no sería demasiado realista utilizar de nuevo el precio de apertura anterior.
-
Otra opción para inferirlo es descargar los datos de otra fuente. Por ejemplo, si me falta el precio de cierre de AAPL con datos descargados de Yahoo Finance, quizás puedo descargar los mismos datos desde Google Finance y ver si allí puedo encontrar el dato que falta.
Evidentemente, esta última opción es mucho más sencilla de hacer con Acciones, Futuros y ETFs dado que cotizan en mercados centralizados y cuando se utilizan temporalidades grandes como datos diarios o semanales. En el caso de FX, cada broker tendrá un dataset parecido pero que no tiene por qué venir de la misma fuente. Y aunque esta solución será generalmente aceptable, su problemática aumenta si necesitamos datos de más resolución (como tick o datos de cada minuto), ya que las diferencias entre distintas fuentes serán más notables como menor sea la temporalidad.
Ya que una imagen vale más que mil palabras, quiero aprovechar para enseñarte las diferencias en los datos dentro del mercado de CFDs sobre divisas (forex). A continuación, puedes ver las diferencias tanto en el Bid como en el Ask de 4 brokers distintos para el instrumento EURUSD el día 15 de junio de 2022, desde las 07:49:15 hasta las 07:49:30 (15 segundos de datos tick).
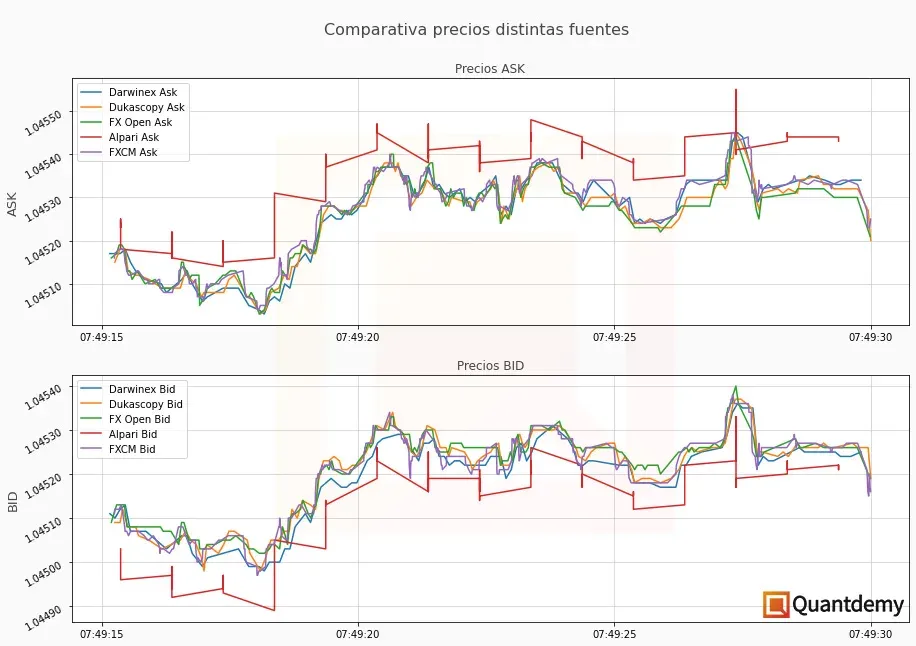
Además, con este tipo de imágenes, se puede ver muy claramente qué proveedores ofrecen un datafeed de mayor calidad. Como ves, solo uno de ellos llama la atención por la limitada calidad de sus datos (en un tipo de cuenta en concreto).
Ajustes de zona horaria
Como sabes, los distintos mercados financieros del mundo funcionan en distintas zonas horarias. A su vez, también es posible que distintos proveedores de datos ofrezcan los históricos de un mismo instrumento en distintas franjas horarias según su localización, algo que es muy importante tener en cuenta si se recopilan datos desde distintas fuentes.
Normalizar los ajustes de fecha de tus datos será un punto crucial durante el proceso de limpieza. Para entenderlo mejor, usemos un ejemplo: imagina que tienes una estrategia en la que utilizas la hora del día para tomar decisiones, como por ejemplo, no colocar órdenes nuevas a partir de las 20:00h de la tarde.
Al realizar un backtest, esto es sencillo: puedes utilizar la propia hora presente en los datos para aplicar ese filtro. Pero, ¿y si esa hora está en la franja horaria de Estados Unidos y tu vives en Europa? Si no tienes este detalle en cuenta, te encontrarás que los resultados de tu backtest y los de la operativa en real no tendrán nada que ver. Por esta razón es tan importante gestionar correctamente las zonas horarias.
Lo que nosotros hacemos para solucionar este problema es convertir siempre los datos a UTC (Universal Time Coordinated) y sin ningún horario de verano aplicado (DST, Daylight Saving Time). Así, disponemos de una base de datos estandarizada donde todos los registros tienen el mismo perfil horario. Para ello, necesitamos conocer de antemano en qué franja horaria se situan los datos inicialmente para poder aplicar la conversión adecuada.
De esta manera, podemos después convertir los datos a la franja horaria adecuada para representar fielmente las fechas y horas correspondientes según las necesidades que tengamos.
Jerarquía de Asks y Bids
Seguidamente, es importante verificar que los precios Ask sean efectivamente mayores que los precios Bid. En teoría, esto es algo que no debería ocurrir. Sin embargo, te sorprenderías con la cantidad de veces que dicha característica se manifiesta en los datos históricos. Fíjate en la siguiente imagen: son distintos momentos del día 14 de junio de 2022 en el EURUSD donde los datos de este proveedor (FX Open) nos muestran precios Bid mayores a los precios Ask.
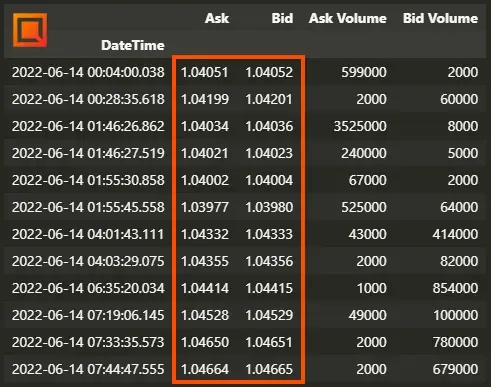
Para hacer que nuestros backtest sean lo más robustos posibles, vamos a considerar que el precio Ask será siempre mayor o igual que el Bid. De esta manera nos ponemos siempre en el “peor de los casos”, donde tendríamos que pagar siempre spread excepto cuando el Bid sea igual que el Ask (algo que sí que permitimos) y nunca tendríamos oportunidades de arbitraje con el spread negativo.
Filtro de Spikes
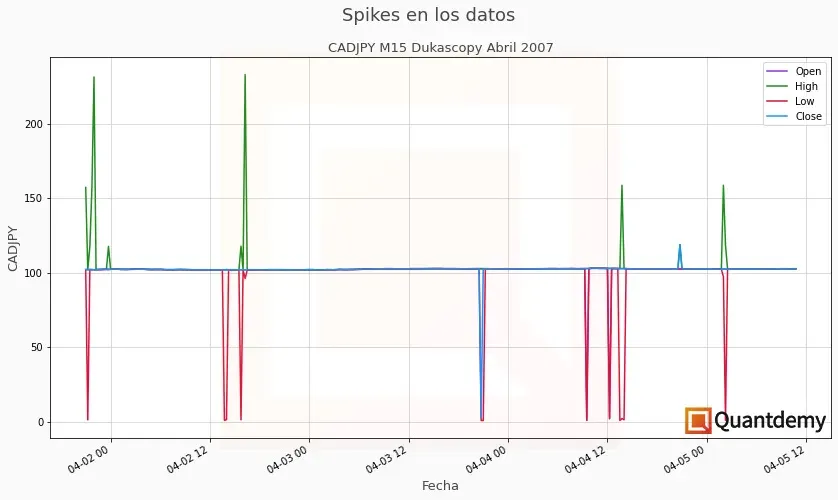
El siguiente paso que hacemos a la hora de limpiar los datos históricos es revisar la presencia de spikes, que son anomalías en los precios en forma de movimientos anormalmente altos o bajos. Por ejemplo, que el precio del EURUSD sea de 1.06726 y al siguiente tick sea de 3.19672. O que el precio de Apple sea de $142 el día 1, de $3718 el día 2 y de $144 el día 3.
Para que puedas ver un ejemplo real, mira lo que ocurre con los datos tick en crudo de Dukascopy para el par de divisas CADJPY en abril de 2007:
Lo siguiente es comprobar que no haya ticks que valgan 0. Se podría decir que esto es una continuación de la detección de spikes, pero es un test que realizamos expresamente. Esto es debido a que muy a menudo, utilizamos cálculos de retornos para los activos. Y si en un momento determinado el valor del activo es 0 y el siguiente precio es cualquier otro número que sea mayor a 0, el retorno sería infinito, lo que hace que ciertos cálculos queden completamente fuera de escala.
Ejemplo: si hoy la acción X vale $100 y mañana vale $110, su retorno ha sido de un 10%. Si hoy la acción Y vale $0 y mañana vale $0.01, su retorno habría sido infinito.
Imagínate lo que sería realizar un backtest con todos estos errores en los datos. Podrías tener una curva de resultados que te llevaría a pensar que la estrategia es ganadora y, sin embargo, sería solo una ilusión, ya que justamente fueron esos spikes que han coincidido con operaciones concretas que han hinchado los resultados finales.
Jerarquía OHLC
En caso de trabajar con datos OHLC (Open, High, Low, Close), que son los 4 puntos necesarios para representar una vela japonesa, deberemos comprobar también que se cumple su jerarquía para evitar errores posteriores. Esta jerarquía se define por las siguientes dos condiciones:
-
El valor Low NO debe ser mayor que los otros valores (pero puede ser igual).
-
El valor High NO debe ser menor que los otros valores (pero puede ser igual).
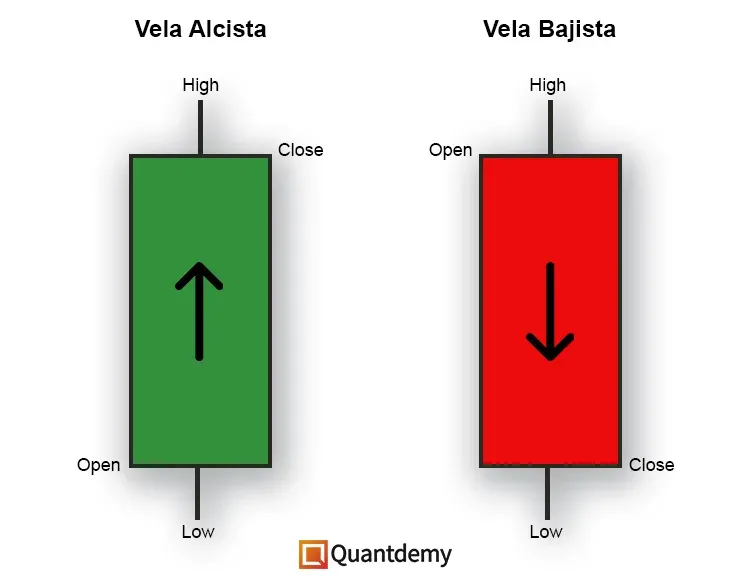
Esto puede parecer obvio, pero de nuevo te sorprenderías con la cantidad de veces que nos hemos encontrado con datos donde el valor del Open es mayor al del High, lo que es evidentemente erróneo. Eso se puede deber a errores ocurridos durante el proceso de resampling (convertir datos de una temporalidad inferior a una superior), a errores en el proceso de captura de dichos datos, etcétera.
Deberás acostumbrarte a comprobarlo todo por ti mismo y a no dar prácticamente nada por hecho.
Es siempre mejor pecar de precavidos a que un error te pase inadvertido y pueda restar precisión a tus backtests. A mi me gusta ver este proceso como una suma de pequeñas victorias que por sí solas no parecen demasiado, pero cuando las pones todas juntas te dan una ventaja increíble.
Comparativa entre fuentes
La siguiente opción es comparar tus datos con distintas fuentes para poder asegurarte que son parecidos y poder filtrar otra anomalías que de otra manera no hubieras podido detectar. Esto es especialmente cierto en los mercados OTC (como los CFDs sobre forex), donde hay distintas fuentes de datos para un mismo activo. En cambio, los mercados centralizados disponen de un libro de órdenes central y compartido por todos los usuarios, lo que crea que los datos provengan de una sola “fuente de la verdad”.
En la siguiente imagen puedes ver cómo todas las fuentes usadas para consultar el precio de un mismo activo son parecidas pero no idénticas. Evidentemente, esta imagen sirve solamente a modo de referencia; representa solamente el EURUSD en temporalidad de un minuto desde las 21h hasta las 22h del día 14 de junio de 2022.
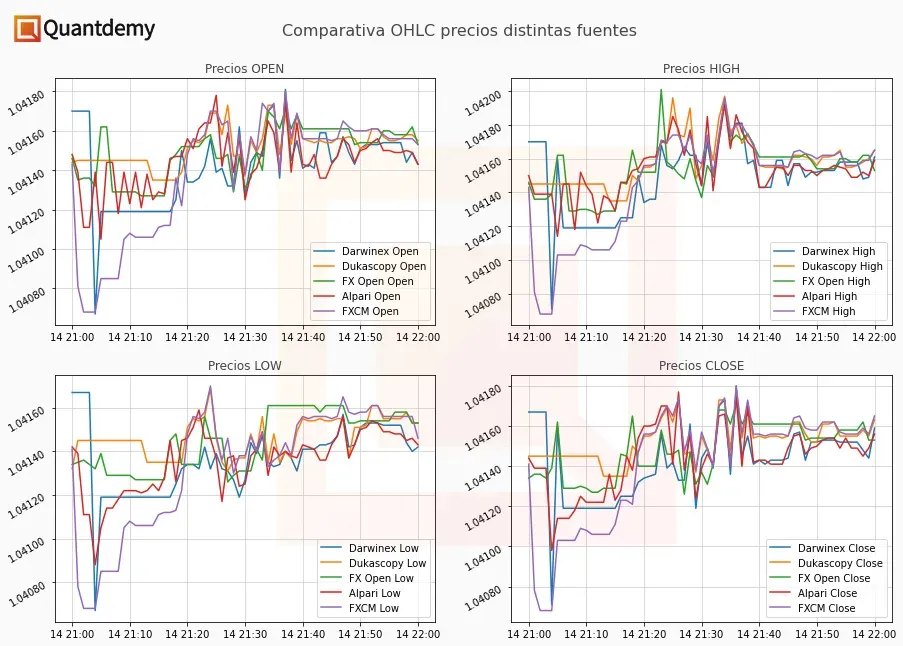
Un detalle a apreciar es que una vez se han resampleado los datos (en este caso convertidos de tick a M1), la diferencia de calidad que veíamos antes con la comparativa de tick data ya no es tan evidente. ¿Cual es la opcion correcta entonces?
Trabaja con los datos históricos del broker con el que vayas a operar.
Construcción adecuada de series temporales
Por último, vamos a hacer mención también a la importancia de construir adecuadamente las series temporales (datos) para hacer backtesting correctamente. Hasta ahora hemos hecho especial énfasis en el mercado de CFDs sobre divisas (aunque las técnicas que hemos visto son perfectamente extrapolables), pero hay algo importante a tener en cuenta si estás diseñando una estrategia de trading para acciones.
Cada asset class tiene sus propias características y particularidades, y son aspectos importantes a conocer si vas a operar en dichos mercados. Para ilustrar este último punto, vamos a hacerlo con un ejemplo: queremos obtener los datos de una empresa para poder hacer backtesting de nuestra estrategia. Para este ejemplo he escogido la empresa AT&T Inc (NYSE: T). El motivo es que es una empresa establecida en el sector de las telecomunicaciones que históricamente ha pagado un muy buen dividendo (ahora verás por qué es importante esto).
Volviendo a la estrategia, imagínate que solo quieres ir en compra (no hacer ventas en corto) y mantienes las posiciones por un largo periodo de tiempo. Evidentemente, este tipo de operativa se beneficiará del cobro de dividendos y deberías decidir si esos dividendos se reinvertirían en la estrategia o no. En el caso de ser así, si al descargar los datos utilizaras los precios de cierre, estarías cometiendo un error muy importante. Fíjate en la imagen:
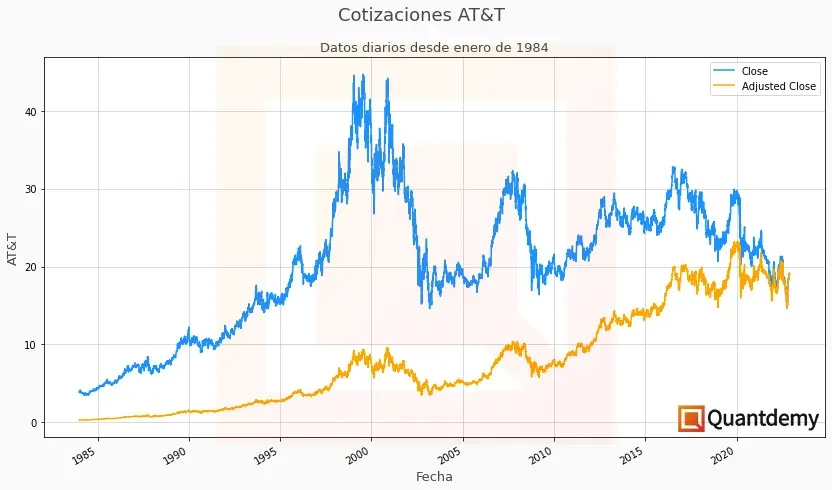
Como ves, las dos series temporales son parecidas, pero distintas. El gráfico naranja representa los precios de cierre ajustados a dividendos y splits, lo que significa que tiene en cuenta la reinversión del dividendo pagado por la empresa en la cotización y los tres splits que ha tenido esta empresa en su historia. Este ajuste se hace automáticamente desde la fecha actual hacia el pasado, de manera que puedas contar con un dataset contínuo y ajustado a los distintos dividendos pagados por la empresa a lo largo de su historia (dado que no siempre han sido los mismos).
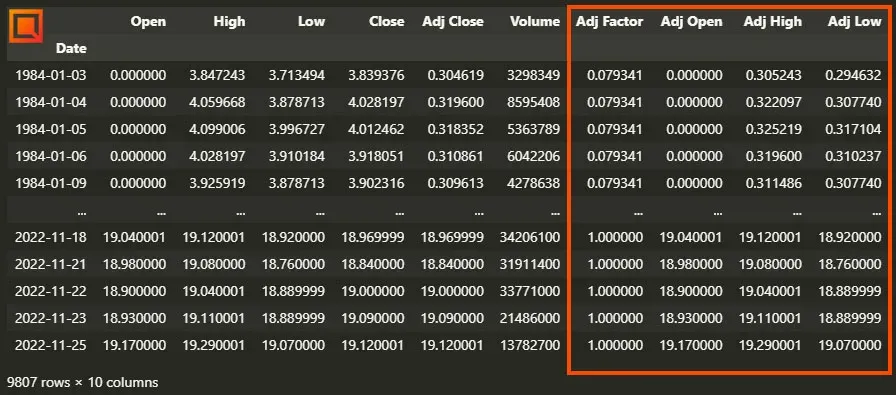
Cuando descargas datos de empresas de fuentes como Yahoo Finance, suelen venir siempre con, al menos, el Adjusted Close (cierre ajustado). Si necesitaras también la apertura, el máximo y el mínimo de las cotizaciones ajustadas a dividendos, lo podrías hacer de una manera muy sencilla. Al tener los precios de cierre y de cierre ajustado, puedes calcular el “factor de ajuste” de cada día (o según la granularidad de tus datos) dividiendo el Cierre Ajustado entre el Cierre. Luego, para calcular el High Ajustado, simplemente multiplica el High por el factor de ajuste. Puedes ver un ejemplo en Python a continuación:
# Importamos las librerías necesarias
import pandas as pd
import yfinance as yf
# Descargamos los datos de Yahoo Finance
data = yf.download('T', start="1984-01-01", end=pd.Timestamp.today())
# Obtenemos el Factor de Ajuste de cada fila de datos
data['Adj Factor'] = data['Adj Close'] / data['Close']
# Obtenemos los Open, High y Low ajustados multiplicando por el Factor de Ajuste en cada fila de datos
data['Adj Open'] = data['Open'] * data['Adj Factor']
data['Adj High'] = data['High'] * data['Adj Factor']
data['Adj Low'] = data['Low'] * data['Adj Factor']Al ejecutar este código, podemos ver cómo se crearían las columnas con los datos Open, High y Low ajustados. Las columnas dentro del recuadro naranja son las que hemos calculado y las que deberíamos usar para nuestro backtest, junto al “Adj Close” original.
Conclusión
Como has podido comprobar, el primer paso antes de podernos centrar de lleno en cómo hacer backtesting correctamente es disponer de datos históricos de calidad. Es un paso que los traders menos experimentados suelen pasar por alto, pero es esencial prestarle la atención que se merece. Como ahora ya sabes, un backtest realizado sobre datos erróneos no sirve de nada y te llevará a conclusiones imprecisas.
Si quieres poder diseñar estrategias de trading ganadoras, tienes que hacer las cosas bien. Y los datos de calidad son siempre el primer punto a tener en cuenta. Por si te interesa, en KomaLogic usamos los datos que ofrece Quantdle. Son de altísima calidad además de económicos, algo que para un trader retail es de máxima importancia.
Al fin y al cabo, vas a poner en risgo tu propio capital cuando comienzes a operar con la estrategia. ¿No crees que vale la pena dedicar el esfuerzo necesario al tratamiento de los datos para poder tener las mayores garantías de éxito en el resto de pasos del proceso de backtesting?
Si todo este tema te ha abrumado un poco, no te preocupes. Es solo cuestión de dedicarle tiempo y de disponer de una guía adecuada. Si tu punto débil es la programación, entonces te encantará nuestro curso para aprender a programar en MQL4 desde 0.
En el próximo artículo seguiremos estudiando en profundidad como hacer backtesting de calidad.
Hasta entonces, espero que este artículo te haya sido de utilidad.
Gracias por tu lectura.
Un saludo,
Martí


