Apreciado trader,
En este artículo de la serie de backtesting pretendo explicarte cómo cuantificar la incertidumbre de un backtest. El objetivo del artículo es también extender mi ponencia sobre este tema el pasado 21 de octubre en la Kedada23 de X-Trader y en la que no pude contestar a todas las preguntas con la profundidad que requerían.
Para que el artículo no se quede solo en un ejercicio teórico, añadiré también código en Python y un CSV descargable con los datos necesarios para que puedas recrear la metodología por ti mismo, ya que creo que esta es la mejor forma de aprender.
¡Comencemos!
Objetivo: cuantificar la incertidumbre de un backtest
Lo primero que podríamos pensar es: ¿y por qué debería preocuparme por esto? ¿qué significa que mi backtest tiene incertidumbre? Para responder a estas preguntas, debemos primero establecer un marco de referencia conceptual acerca de la naturaleza de los precios y cómo se crean.
Ser capaz de cuantificar la incertidumbre tiene muchas ventajas, siendo la principal la de poder evaluar la variabilidad a la que podría estar sujeto tu experimento.
En otras palabras, midiendo la incertidumbre de tu backtest podrías estimar la probabilidad de que tu estrategia fuera realmente perdedora, aun cuando el backtest hubiera resultado ganador.
Esta información podría serte muy útil a la hora de asignar un riesgo determinado a dicha estrategia, ya que si la probabilidad real de pérdida es mayor a lo que tu esperabas, quizás podrías ejecutar dicha estrategia con menos riesgo de lo que tenías pensado inicialmente.
Sin embargo, antes de continuar, veamos qué significa incertidumbre en este contexto:
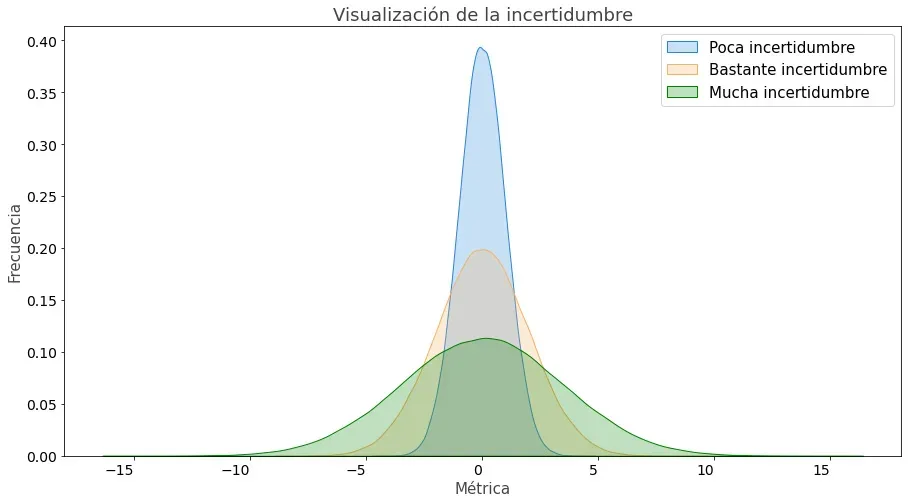
Si esta imagen no te aporta demasiada información, no te preocupes. Sigue leyendo y verás como todo va cobrando sentido poco a poco.
Los precios como resultados de modelos desconocidos
Podemos entender el precio de un instrumento como el resultado de un proceso desconocido (un modelo estadístico). Este modelo es una caja negra para nosotros, ya que desconocemos los parámetros que lo gobiernan y la única información que tenemos son los propios precios que dicho modelo genera y que recibimos en nuestro terminal de trading.
Imagínatelo como una caja negra en la que dentro hay infinitas papeletas con un número escrito. Cada número es un retorno, por ejemplo +1%, -0.7%, +2%, etcétera. Al cierre del mercado de cada día, el retorno de la jornada equivaldría a haber recibido una de las papeletas que había en la caja.
El problema es que no podemos acceder a esa caja, de manera que no sabemos cuántas papeletas hay dentro, qué retornos hay escritos en ellas y ni siquiera si esas papeletas se sustituyen por otras de vez en cuando o se quedan allí para siempre. Esta es nuestra principal fuente de incertidumbre.
Sin embargo, lo que sí sabemos es lo que ha salido de la caja: las series temporales de los precios (las papeletas que hemos recibido). Estos precios los conocemos y los podemos medir, de manera que podemos estimar este modelo desconocido que lo gobierna. Insisto en la importancia de que es una estimación; en ningún momento sabemos con certeza absoluta cómo es el modelo que existe dentro de la caja negra.
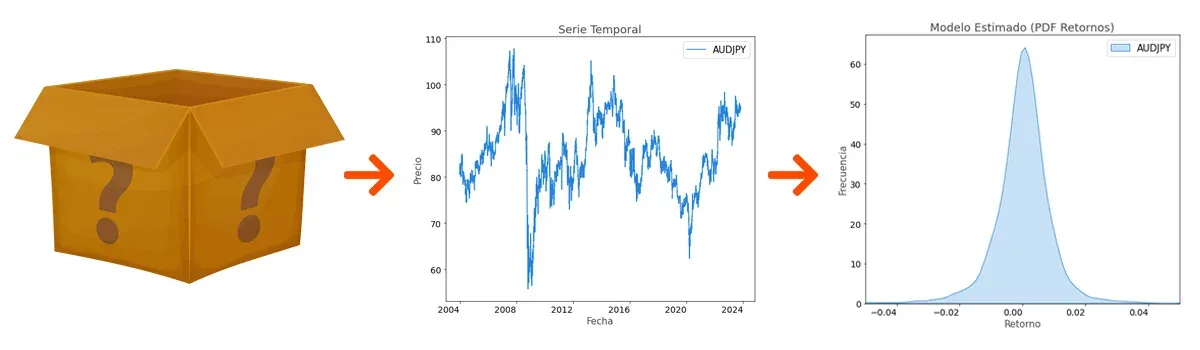
Esa estimación, ese modelo que nosotros construimos basándonos en las observaciones que hemos podido hacer del mundo real, lo representamos en forma de Función de Densidad de Probabilidad. Es decir, asignamos una probabilidad determinada a cada rango de retorno posible basándonos en los retornos que hemos visto hasta ahora. Por ejemplo, podríamos estimar que la probabilidad de obtener un retorno mayor al 0% es del 59%.
Esto significa algo muy importante:
Cuantas más observaciones (más datos o “papeletas”), más representativo será nuestro modelo.
Sin embargo, estaremos siempre limitados a la cantidad de datos históricos que tengamos a nuestra disposición. Incluso así, por muchos datos históricos a los que seamos capaces de acceder, siempre nos quedará la posibilidad de que mañana el mercado haga algo que no había hecho nunca antes en su historia. Esta incertidumbre constante es algo con lo que los traders debemos aprender a convivir.
“Si quieres asegurarte de tener los mejores datos para tus backtest, Quantdle es tu herramienta definitiva. Pruébala gratis aquí”.
El backtest como un modelo de caja negra
Del mismo modo que ocurre con los precios de los distintos instrumentos financieros, podemos entender también un backtest como una serie temporal fruto de un modelo estadístico que desconocemos. Deja que me explique.
Conocemos perfectamente las normas de nuestra estrategia (por ejemplo, compramos cuando la media X cruza a la media Y). Estaremos de acuerdo que aquí no hay ninguna incertidumbre. Sin embargo, dichas normas las aplicamos sobre el precio de un activo o grupo de activos que, como hemos visto, sí tienen una incertidumbre asociada.
Damos por hecho que el backtest lo hemos hecho siguiendo unas buenas prácticas. Un backtest mal hecho o sobreoptimizado nos dará resultados demasiado optimistas y todo el proceso posterior de cuantificar la incertidumbre no nos aportará ningún valor.
Entendiendo la fuente de la incertidumbre
Hemos dicho que un backtest es solamente la materialización de unas normas sobre una serie temporal (el precio de un activo) fruto de un modelo desconocido. Es decir, nuestro backtest se ha aplicado únicamente a “esa” serie temporal que se ha generado, pero no a todas las otras que podrían haber sido. Y es precisamente esa incertidumbre la que se traslada a nuestro backtest.
Para que puedas visualizarlo fácilmente, fíjate en la imagen que encontrarás a continuación. En ella hay seis series temporales distintas que provienen exactamente de la misma distribución (el mismo modelo).
Cada una de ellas podría representar perfectamente el precio de un instrumento. Por decirlo de una manera más filosófica, cada curva podría haber sido el precio que, por ejemplo, hubiera tenido el EURUSD en un pasado alternativo (ignorando los valores del eje Y).
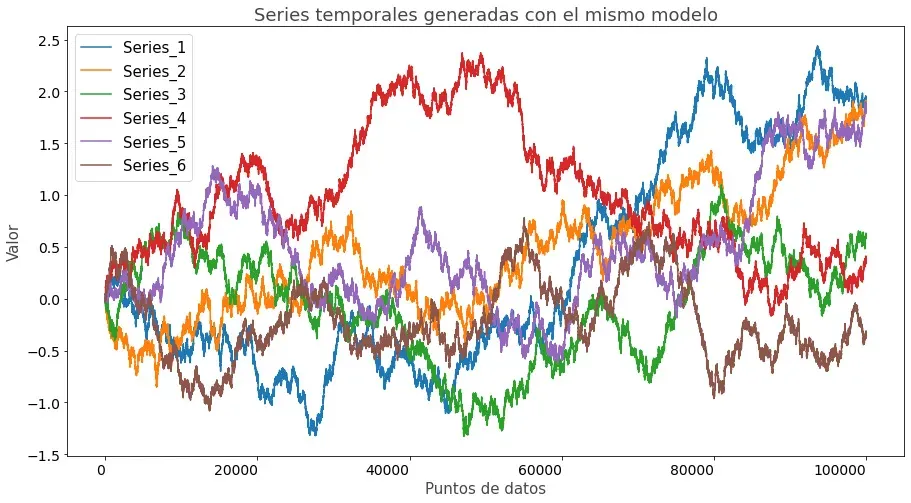
Sin embargo, nosotros solo podemos observar uno de los caminos, el que el instrumento en cuestión ha tenido en el pasado. Y es sobre ese precio observado sobre el que nosotros podemos aplicar las normas de nuestra estrategia y obtener el resultado de nuestro backtest.
Es decir, hemos hecho el backtest sobre uno de los posibles pasados alternativos que podrían haber ocurrido.
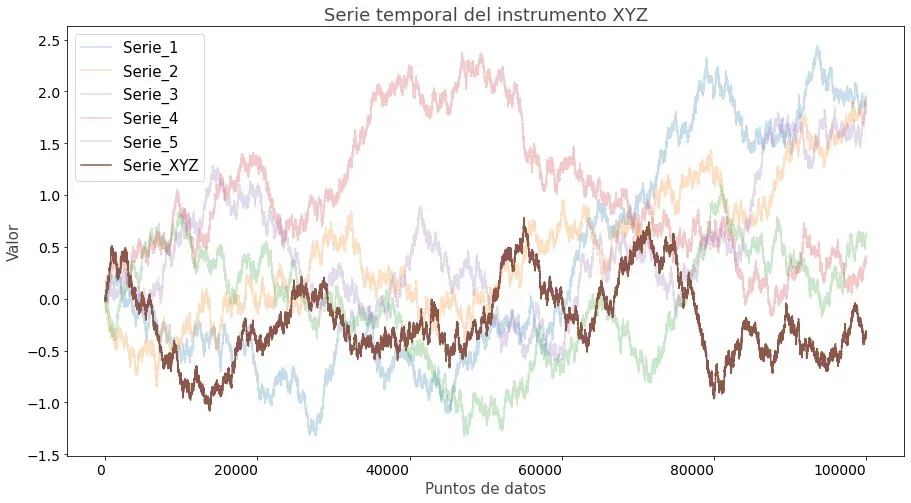
Siguiendo con el ejemplo de la imagen, los precios reales que sí habrían ocurrido son los del instrumento XYZ, mientras que los otros precios son los que también podrían haber ocurrido. Entonces, como sólo tenemos acceso a los precios que sí han ocurrido, sería el instrumento XYZ sobre el que podríamos realizar nuestro backtest.
Pero, ¿cómo podemos tenerlos en cuenta si los “otros pasados” no han ocurrido?
Evidentemente, sólo podemos usar la información que tenemos a nuestro alcance (en este caso los resultados del backtest) para simular esos pasados alternativos. Como ya imaginarás, la calidad de dicho proceso dependerá directamente de la cantidad de datos de los que dispongamos: la cantidad de trades de nuestro backtest o el histórico disponible.
Por otro lado, también será determinante la calidad del proceso de backtest que se ha llevado a cabo.
Insisto: un backtest sobreoptimizado con unos resultados demasiado optimistas no nos aportará ninguna información de valor.
Teniendo esto claro estaremos ya en disposición de poder calcular la incertidumbre alrededor de nuestro backtest.
Calculando la incertidumbre alrededor de nuestro backtest
Lo primero que deberemos tener en cuenta es que este cálculo de la incertidumbre no es sobre el backtest en sí, sino sobre una de las mediciones que podemos hacer sobre él. Por ejemplo: ¿cuál es la incertidumbre alrededor del porcentaje de acierto que tiene mi backtest?
Es decir, queremos estimar cuánta variabilidad hay alrededor de una métrica que podemos medir sobre nuestro un backtest. Estas métricas podrían ser el retorno medio, la volatilidad, el Sharpe Ratio, el drawdown máximo, etcétera.
En nuestro caso vamos a utilizar la Ratio de Sharpe como ejemplo, ya que al ser una medida de retorno ajustada al riesgo lo hace más interesante.
Para ello, lo que vamos a hacer es calcular la distribución muestral del SR de nuestro backtest utilizando un proceso de resampling con repetición no paramétrico (non-parametric bootstrapping).
Non-parametric Bootstrapping paso a paso
El proceso del non-parametric bootstrapping, pese a su peculiar y quizás intimidante nombre, es extremadamente sencillo. Para los curiosos, el hecho de que sea non-parametric implica que no hacemos ninguna suposición previa (por eso es sin parámetros) sobre cómo las observaciones (en nuestro caso los SR) están distribuidas, sino que generamos las simulaciones a partir de los datos en crudo.
El proceso se basa en crear distintas N simulaciones de nuestro backtest utilizando los datos de los trades disponibles escogidos de manera aleatoria cada vez (resampling), permitiendo coger más de una vez el mismo resultado (con repetición). Como imagino que estarás asumiento, este proceso es, efectivamente, un tipo de simulación de Monte Carlo.
Nota: el proceso implica que los trades son independientes entre sí. El resampling elimina cualquier autocorrelación existente en los datos originales.
Si esto supone un problema, siempre puedes utilizar bloques de operaciones para intentar mantener cualquier autocorrelación existente en ellos. Por ejemplo, en lugar de resamplear operaciones individuales, lo puedes hacer con bloques de 50 trades.
Paso 1: creación de una simulación sintética
Lo primero que haremos será crear un backtest alternativo cuya longitud sea exactamente la misma que la del backtest original. Esto significa que si nuestro backtest tenía 10000 trades, cada uno de los backtests sintéticos deberá tener también 10000 trades.
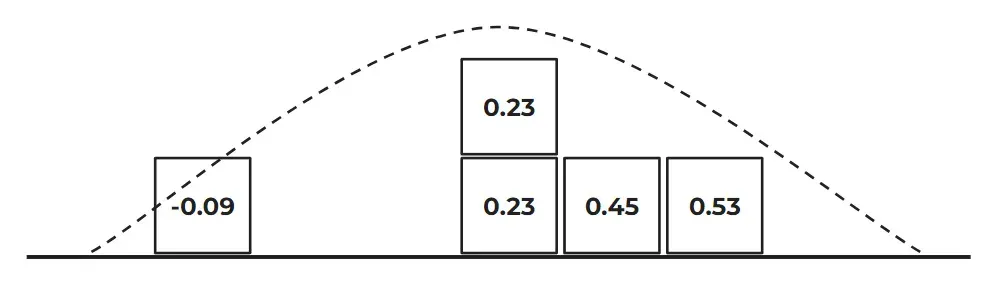
Esto lo haremos escogiendo, por cada una de las 10000 posiciones de nuestro backtest sintético, un trade del backtest original al azar, pudiendo elegir más de una vez el mismo trade. Con la siguiente imagen te quedará más claro (para nuestro ejemplo y para poderlo representar fácilmente, usaremos un backtest hipotético con 6 trades):
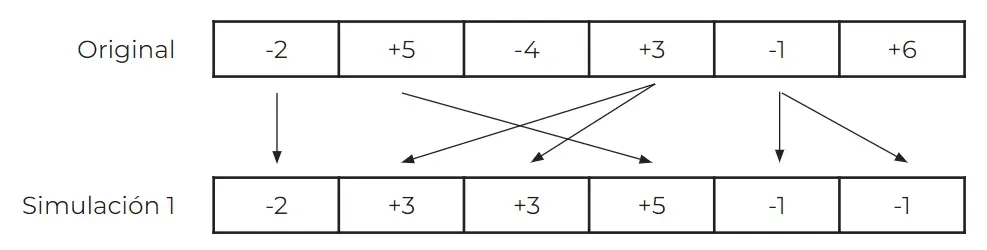
En esta primera simulación de la imagen, puedes ver que tanto el 4º valor (+3) como el 5º (-1) se han seleccionado 2 veces cada uno, mientras que el 3º (-4) y el 6º (+6) no se han seleccionado ninguna vez.
Paso 2: cálculo de la métrica de interés
Ahora que ya tenemos un primer backtest sintético generado, podemos calcular la métrica que nos interese. Recuerda que en nuestro ejemplo estamos utilizando el Sharpe Ratio, pero podría ser perfectamente también el drawdown, el retorno medio, la desviación estándar, el % de acierto, etc.
Es importante guardar la métrica, ya que será crucial para el siguiente paso. Ahora, solo faltará volver al paso 1 y repetir este proceso N veces (tantas como simulaciones queramos realizar).
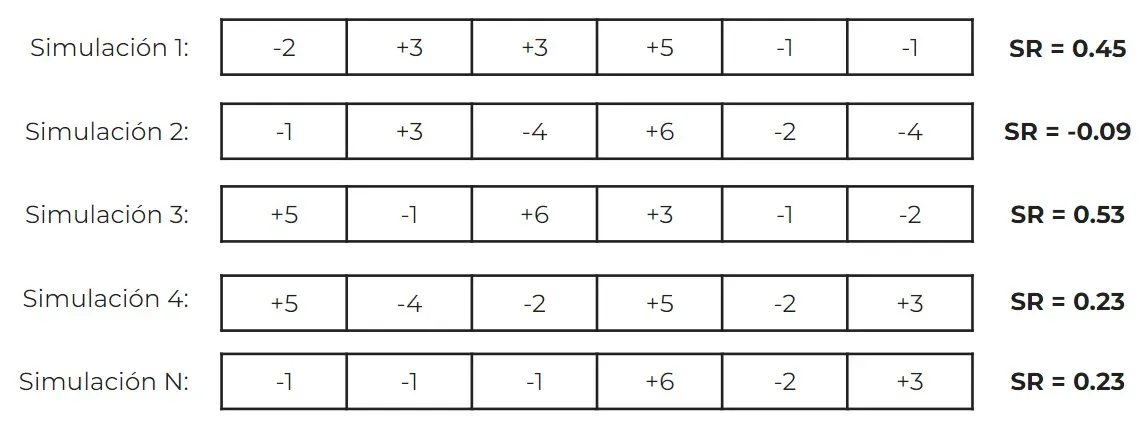
Paso 3: construcción de la distribución muestral
Finalmente, solo nos quedará construir la distribución muestral de nuestra métrica para poder observar qué tan dispersos están los valores que hemos recogido fruto de nuestra simulación.
Para ello, crearemos un histograma que nos servirá para poder evaluar las probabilidades asociadas que podemos esperar de cada intervalo de valores. Esto es así ya que, al final, la distribución muestral no es nada más que la función de densidad de probabilidad de nuestra métrica. No te preocupes si no acabas de entender esto, ya que encontrarás este concepto puesto en práctica en un ejemplo más adelante en el artículo.
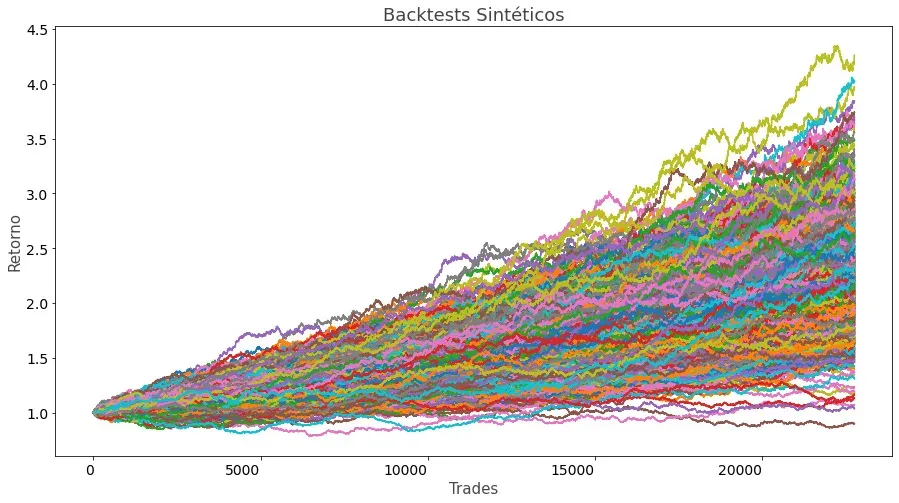
Simulando 1 millón de escenarios con Python
A continuación te presento un ejemplo real de este proceso con un total de un millón simulaciones para que, visualmente, puedas comprender todo el proceso. Además, añadiré el código en Python para que puedas crear tu propia versión del experimento.
Este va a ser un experimento computacionalmente muy intensivo, por lo que es extremadamente importante usar las librerías adecuadas para acelerar el proceso. Como verás, reduciremos al mínimo el uso de estructuras nativas de Python (bucler for, listas, appends, etc) y maximizaremos el uso de librerías como NumPy y Pandas, que hacen uso de módulos precompilados en C que nos darán una velocidad altísima.
Verás también como utilizar conceptos más propios de C/C++ que de Python, como el de predefinir arrays de una longitud determinada para evitar tener que asignar memoria de forma dinámica en cada iteración del bucle for principal. Esto nos ayudará a crear un código rapidísimo.
Primero importamos los módulos necesarios: NumPy, Pandas y tqdm (una librería para agregar una barra de progreso).
# Importamos módulos y clases necesarios
import numpy as np
import pandas as pd
from tqdm import tqdmA continuación definiremos el número de simulaciones a llevar a cabo y crearemos los elementos necesarios para llevar a cabo la simulación, así como el bucle principal de cálculo (pasos 1 y 2).
Ahora a por el código:
# Número de simulaciones
simulations = 1000000
# Cargamos el dataframe con los datos de retornos del backtest
# y pasamos la columna RETURNS a una pd.Series
return_df = pd.read_csv('Backtest_Returns_Quantdemy.csv', parse_dates=['TIME_IN'], index_col='TIME_IN')
return_series = return_df.RETURNS
# Definimos la longitud total del dataset (número de trades). Son 22775 trades en total
dataset_length = len(return_series)
# Convertimos la pd.Series a una Numpy array para poder acelerar el proceso de random sampling
return_array = np.array(return_series)
# Creamos una array vacía llamada alt_sharpes (alternative_sharpes) para guardar los resultados de la simulación.
# Así evitamos tener que asignar memoria de manera dinámica durante la ejecución
alt_sharpes = np.zeros(simulations)
# Definimos el factor anualizador para el SR, entendiendo que hay 252 días de trading por año
annualizing_factor = np.sqrt(252)
# Definimos el bucle principal. Este bucle sí que es "pythonic", pero es el único que necesitamos
for sim in tqdm(range(simulations)):
# Creamos un backtest alternativo con repetición usando el método choice
alt_history = np.random.choice(return_array, size=dataset_length)
# Calculamos el SR de ese backtest alternativo y lo guardamos en la numpy array alt_sharpes
alt_sharpes[sim] = np.mean(alt_history) / np.std(alt_history) * annualizing_factor¡Y listo! Con un código muy compacto y elegante hemos conseguido encapsular todo el proceso de bootstrapping.
La librería tqdm me permite ver que en mi ordenador consigo alrededor de unas 2900 iteraciones del bucle for principal por segundo, lo que hace que el proceso termine en unos 6 minutos para 1 millón de simulaciones.
Es decir, rellenar 2900 veces por segundo una array de 22775 posiciones de manera aleatoria con repetición y calcular su SR:
1%| | 5116/1000000 [00:01<05:40, 2918.42it/s]
Para que te hagas una idea de la velocidad de este proceso y de la importancia de optimizar el código cuando trabajamos con grandes cantidades de datos, fíjate en los resultados del mismo proceso hecho con estructuras nativas de Python y utilizando la librería estándar. Se consigue solamente una velocidad de unas 100 iteraciones por segundo con un tiempo total de 2 horas y 50 minutos:
0%| | 2826/1000000 [00:28<2:47:38, 99.13it/s]
Puesto en números, con nuestra optimización hemos conseguido realizar el mismo proceso un 3400% más rápido. ¡Casi nada!
Que nadie te diga nunca más que Python es lento cuando se usan las librerías adecuadas 😜
Veámos lo que hemos hecho:
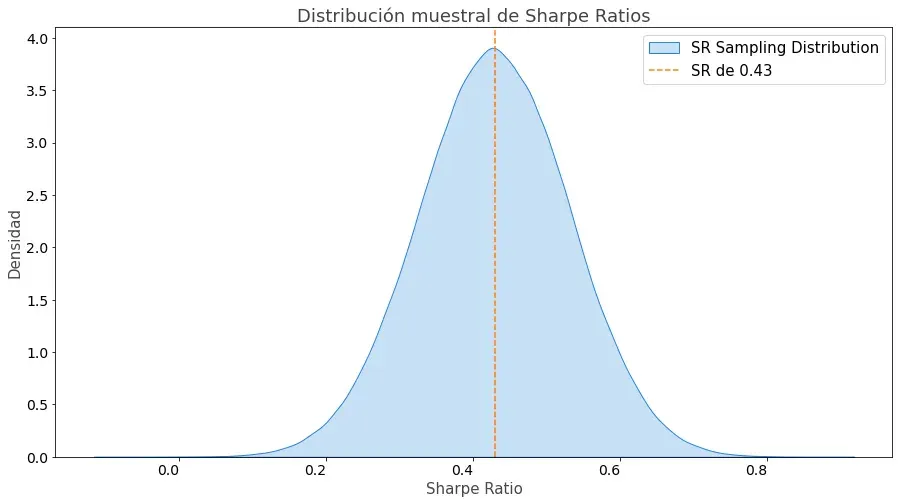
Lo que representa una distribución muestral de Sharpe Ratios (paso 3) como la siguiente:
Esperando un poco de Normalidad (Teorema del Límite Central)
Una vez tengamos nuestra simulación lista, estaremos finalmente en disposición de poder comenzar a sacar conclusiones. Esto lo haremos calculando las probabilidades asociadas a los distintos intervalos como, por ejemplo, cuál es la probabilidad de que el Sharpe Ratio real de la estrategia sea mayor a 1 si en el backtest es de X.
Pero antes de poder llegar a eso, necesitamos alguna herramienta matemática que nos permita poder realizar estos cálculos e, idealmente, que sea de manera rápida y fácil.
Por suerte para nosotros, existe una propiedad muy interesante de las distribuciones muestrales:
Por el Teorema del Límite Central, para un N suficientemente grande, una distribución muestral se aproxima a una distribución normal.
La buena noticia es que es muy sencillo trabajar con distribuciones normales. Esto se debe, primero de todo, a que una distribución normal es simétrica y que está completamente definida solamente por dos parámetros: la media y la desviación estándar.
Esto significa que podremos tratar nuestra distribución muestral como si fuera una distribución normal sin ningún problema. Si necesitas una demostración, a continuación puedes ver la distribución de los SR superpuesta a una distribución normal.
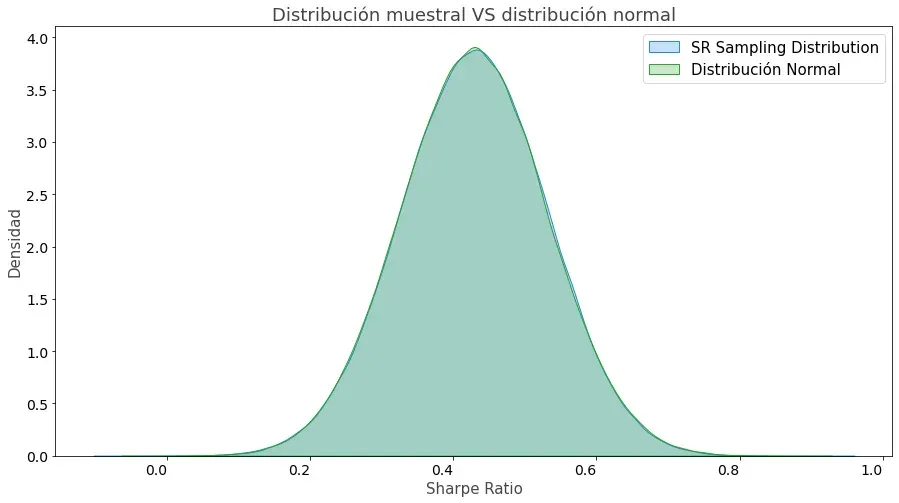
Como ves, siempre que el número de simulaciones sea lo suficientemente grande, podemos tratar nuestra distribución muestral como si fuera gaussiana sin ningún problema.
Además, la parte más útil para nosotros es que podremos hacer uso de librerías como SciPy (Science Python) que nos permitirán trabajar con éstas distribuciones de una manera muy fácil y eficiente.
Calculando las probabilidades de manera teórica
Finalmente, ya tenemos todas las herramientas para poder calcular las probabilidades asociadas a nuestra métrica y cuantificar así la incertidumbre asociada a ella.
Como te había dicho anteriormente, la distribución muestral no es nada más que la función de densidad de probabilidad de nuestra métrica. Por esta razón, podemos calcular las probabilidades asociadas a distintos intervalos simplemente calculando el área que hay debajo de la curva entre dichos valores.
De manera general, podríamos decir que la probabilidad de que el SR esté entre [a, b], es decir, entre a y b, es de:
Donde f(x) es la función de densidad de probabilidad (PDF), que en nuestro caso equivale a la distribución muestral.
Debes tener en cuenta que, por definición, el área total debajo de la curva de una función de densidad de probabilidad es 1 (el 100% del área). Como sabes, las probabilidades tienen un valor entre 0 y 1, y el área total debajo de la curva implica la probabilidad asociada a que el valor de la métrica esté entre -∞ e ∞. Esta probabilidad es de 1, el 100%:
Por esta razón, la probabilidad de que el Sharpe Ratio sea de 0.6 o menor equivale a calcular el área que hay debajo de la curva desde -∞ hasta 0.6. Esto es equivalente a integrar la distribución muestral entre dichos intervalos.
Si lo que queremos calcular es la probabilidad de que el SR sea mayor a un valor determinado a, basta con calcular la probabilidad de que sea menor a dicho valor y luego restar este valor a 1:
Veámslo en un ejemplo:
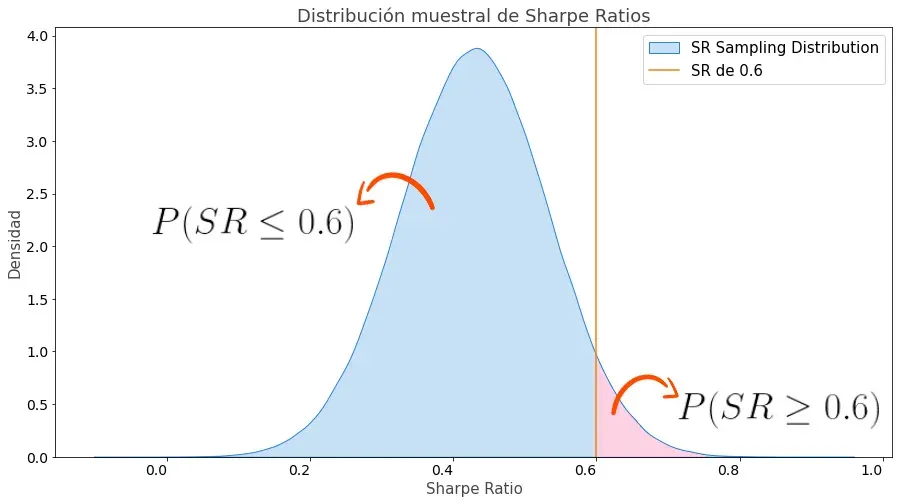
El área debajo de la curva entre -∞ y 0.6 (el área azul) es de 0.9523. Dicho de otra manera, la probabilidad de que el SR sea menor o igual a 0.6 es del 95.23%:
Esto significa que la probabilidad de que sea mayor o igual a 0.6 (el área rosa) será de 1 – 0.9523 = 0.0477, o de un 4.77%:
En términos más técnicos, lo que estamos diciendo es que hay un 4.77% de probabilidad de que el SR verdadero se encuentre en la zona que describe la curva de la distribución muestral entre 0.6 e ∞.
Calculando las probabilidades fácilmente con Python
Ahora que ya hemos aclarado la teoría, creo que estaremos de acuerdo en que ponernos a calcular integrales no es algo que suela apetecernos demasiado. Por suerte para nosotros, tenemos herramientas en Python a nuestra disposición que nos ayudarán a realizar esta tarea de manera extremanademente sencilla y eficiente.
¿Recuerdas que hemos demostrado también que podíamos aproximar la distribución muestral como una distribución normal? Pues es ahora cuando esta propiedad nos es más útil. Veámos como calcular dichas probabilidades en Python:
# Importamos los módulos y clases necesarias
from scipy import stats
import numpy as np
# Definimos la media y desviación estándar nuestra distribución normal
# Usamos la variable alt_sharpes que es un numpy array con todos los SR de la simulación
dist_mean = alt_sharpes.mean()
dist_std = alt_sharpes.std()
# Definimos el SR sobre el que queremos calcular las probabilidades
sr_objetivo = 0.6
# Calculamos el área debajo de la curva desde -infinito hasta nuestro SR objetivo
# usando la Función de Distribución Acumulativa (CDF)*
cum_norm_dist = stats.norm.cdf(sr_objetivo, dist_mean, dist_std)
# Calculamos la probabilidad de que el SR sea mayor o igual a nuestro SR objetivo
# y la imprimimos con dos decimales
prob = 1 - cum_norm_dist
print(f'Probabilidad de que el SR sea mayor o igual a {sr_objetivo}: {prob*100:.2f} %')*Puedes encontrar más información acerca de la Función de Distribución Acumulativa aquí.
Ejecutando este código, podríamos ver que el resultado de la instrucción print sería: Probabilidad de que el SR sea mayor que 0.6: 4.77 %
Conclusión
¡Y alcanzamos al final! Felicidades si has llegado hasta aquí; sé que este artículo ha sido algo más extenso de lo que suelen ser habitualmente. Pero quería aprovechar la ocasión para poder ampliar el contenido de la presentación de la pasada Kedada23 de X-Trader a la que hacía referencia al inicio, y poder añadir las respuestas a las distintas preguntas que recibí.
Como conclusión, recuerda que un backtest es una herramienta muy útil para hacernos una idea de cómo podría haberse comportado una estrategia en el pasado, pero que esta evaluación lleva consigo cierta incertidumbre que resulta necesario evaluar.
Ser capaces de cuantificar de manera robusta esta incertidumbre nos permite tener una perspectiva mucho más amplia de los resultados que nuestra estrategia podría desempeñar.
A su vez, nos permite también comprender que no debemos tomar un backtest como dogma de fe, ya que un backtest por sí solo no garantiza nada.
Por otro lado, es muy importante comprender también que las simulaciones que hemos llevado a cabo en este artículo se basan en los datos del backtest.
Si dicho backtest no se ha realizado de manera adecuada, todas las conclusiones que saquemos de él serán erróneas, incluso la metodología presentada en este artículo. Un backtest sobreoptimizado resultará en una menor incertidumbre de la real en las métricas, lo que podría llevarte a asumir más riesgos de los que deberías basándote en información incompleta.
¡Y esto es todo! Como siempre, espero que este artículo te haya aportado valor.
Gracias por tu lectura,
Martí