Apreciado trader,
En esta segunda entrega de la serie de artículos dedicados a cómo hacer backtesting de calidad, voy a explicarte cómo validar un backtest utilizando los conceptos de datos IS y OOS. Hasta ahora ya hemos visto cómo procesar y limpiar los datos históricos con los que vamos a ejecutar nuestro backtest, así que ha llegado el momento de comenzar a preparar el experimento.
La validación de un backtest es muy imporante, ya que es el proceso mediante el cual podremos verificar que nuestra estrategia es robusta y que tiene pocas probabilidades de haber sufrido de una sobreoptimización u overfitting.
Sin embargo, no hay una sola manera de afrontar este problema; existen otras técnicas como el Método Walk Forward que persiguen el mismo objetivo. Pero por ahora, no te preocupes si aún no conoces el significado de éstos términos; los vamos a ir descubriendo poco a poco durante este artículo.
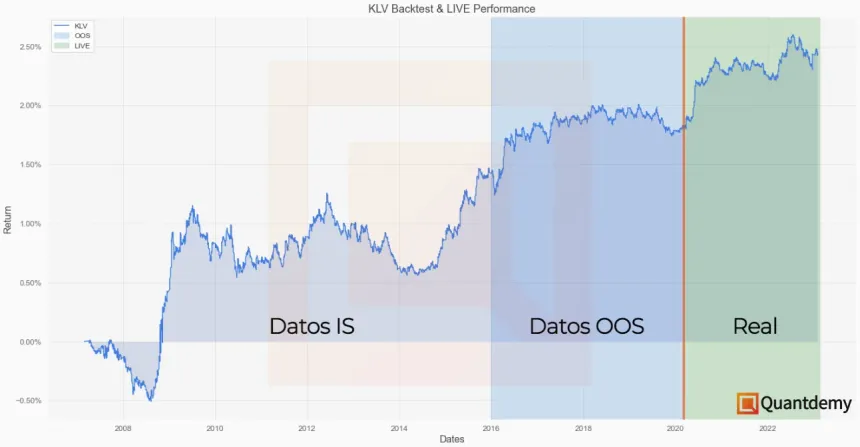
Para que todo este ejercicio no sea tan teórico, voy a guiarte con el ejemplo de KLV, nuestra estrategia real cuyo track record puedes encontrar en Darwinex.
Soy consciente también de que quizás esperabas que el backtest fuera algo más rápido y sencillo de ejecutar, pero necesita de una planificación específica para hacerse correctamente.
Tener en cuenta los pequeños detalles y seguir los procesos adecuados es lo que separa a los traders profesionales de los aficionados. La sistematización te ayudará también a aumentar notablemente tus probabilidades de éxito.
En este momento, vamos a suponer que ya tenemos los datos listos y es el momento de preparar el experimento. Pero… ¿qué hacemos a continuación? Comenzaremos por escoger los rangos de datos que vamos a utilizar en nuestro backtest.
Cómo validar un backtest: rango de datos
En este punto, tenemos nuestra estrategia codificada y los datos históricos (limpios y procesados) de los instrumentos en los que queremos realizar la evaluación.
Podría parecer que lo último que queda es cargar nuestros datos a la plataforma de backtesting, seleccionar la estrategia y darle al botón “comenzar”, ¿verdad? Sin embargo, hay algunas consideraciones que debemos tener en cuenta antes de comenzar con el proceso.
La primera duda que te puede surgir en este punto es si deberías utilizar todos los datos que tienes disponibles para realizar el backtest. Evidentemente, cuantos más datos utilices mejor, pero hay que hacerlo de una manera determinada. Al contrario de lo que podría parecer intuitivamente, no podemos realizar el backtest directamente sobre todos nuestros datos disponibles, sino que debemos dividir estos datos en dos rangos distintos: los datos de muestra (IS de in-sample) y los datos fuera de muestra (OOS de out-of-sample).
“Recuerda que todo este proceso de Backtesting tendrá unos resultados sujetos a errores si nuestros datos no son de calidad. Descubre cómo Quantdle puede facilitarte la vida en este aspecto.”
Tal y como te había comentado anteriormente, vamos a utilizar el ejemplo de KLV para seguir este proceso con un caso real y práctico. Cuando estábamos preparando la estrategia para ponerla a funcionar en la plataforma de Darwinex (en enero de 2020), teníamos datos de 10 instrumentos distintos desde el 01/01/2007 hasta el 31/12/2019. Esto nos dejaba con 13 años de datos históricos que teníamos que dividir en dos datasets distintos.
Datos In-Sample (IS)
Lo primero que tendremos que hacer es definir el rango de datos que vamos a utilizar para la verificación y optimización (si fuese necesaria) de nuestra estrategia.
En nuestro caso, y siguiendo lo que hacemos normalmente en KomaLogic, utilizamos alrededor de un 66% de los datos disponibles como IS y el 33% restante como OOS. Siguiendo el ejemplo que te proponía, esto significa que para el periodo IS utilizamos los datos desde 2007 hasta 2015. Esto son 9 años de datos que, aproximadamente, corresponden al 66% de 13 años de datos totales. En realidad, son un 70% de datos IS para no partir el año 2015 por la mitad, ya que el 66% equivaldría a 8.58 años.
La elección de dicho periodo debe tener también en cuenta ciertos aspectos, ya que:
Es muy importante que dentro del periodo de datos IS haya la mayor cantidad de condiciones y ciclos de mercado posibles (por ejemplo, la crisis financiera de 2008).
Inclusión de ciclos de mercado
Deja que te ponga un ejemplo para que puedas entender bien la importancia de este punto.
Imagínate que estás diseñando una estrategia que opera el índice S&P500 y decides que tus datos IS sean desde enero de 2009 hasta diciembre de 2017. Estamos de acuerdo en que, aparentemente, es una buena eleción, ya que durante este periodo hay algunos eventos relevantes como la Crisis Europea de Deuda Soberana en 2011 o el referéndum del Brexit en 2016.
Sin embargo, habrías escogido uno de los periodos más alcistas de la historia, y cualquier estrategia desarrollada u optimizada durante esas fechas daría un peso demasiado elevado a las operaciones en largo (compra) y subestimaría los riesgos reales de este índice.
Un backtest realizado durante ese tiempo también podría hacer que te confiaras demasiado. Los resultados serían, probablemente, demasiado optimistas, haciéndote operar en real con un nivel de apalancamiento superior al que habrías definido si hubieras seleccionado un periodo más amplio de tiempo para tus datos IS. Esto se debe a la escasa volatilidad del S&P durante el periodo definido para el experimento.
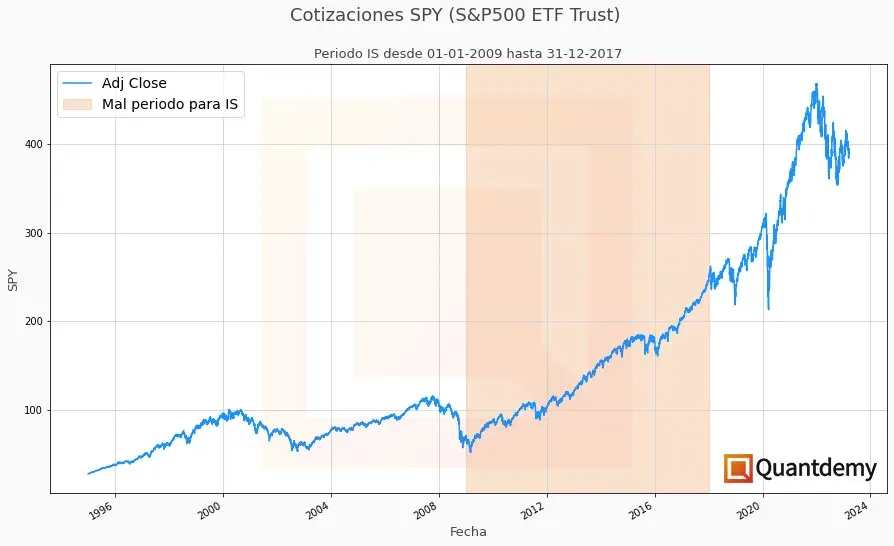
Tendrías una estrategia que parecería increíble en el backtest, pero que sería muy peligrosa de operar en real, ya que habría subestimado el riesgo del mercado al no haberse encontrado con ningún periodo verdaderamente difícil durante ese tiempo (como la Crisis Dot-com en los 2000 o la Crisis Financiera de 2008). ¿Cuál hubiera sido entonces el resultado? Un primer susto en 2018, y ya te puedes imaginar en 2020 con el Coronavirus…
Esta es la razón por la que se suele comentar que cuantos más datos tengas, mejor. Vas a querer probar tu estrategia en los peores periodos para ver cómo se comportó entonces, ya que será en los tiempos difíciles cuando te pondrás a prueba realmente como trader.
La única manera de estar preparado para cuando lleguen los momento complicados en el mercado es que tengas una referencia realista de lo que ocurrió en otras ocasiones y en la que puedas confiar para seguir operando con tu sistema.
Objetivos de los datos IS
En este periodo de 9 años (nuestro periodo IS), es donde, primero de todo, verificaremos que el código funciona correctamente, probaremos nuestra hipótesis, ajustaremos las reglas, las evaluaremos, y podremos optimizar ciertas variables si fuera necesario. Veamos estos puntos:
-
Verificación del código: comprobaremos visualmente que la estrategia compra y vende cuando debe, que sale del mercado correctamente, etc. La idea es verificar que la lógica del código es correcta y detectar cualquier error que pudiera haber. Por ejemplo, si tienes programado que todas las operaciones se cierren el viernes para evitar algún posible gap durante el fin de semana, deberás comprobar que efectivamente las operaciones se cierran cuando deben y que no llegas al lunes con operaciones abiertas.
-
Prueba de la hipótesis: comprobaremos también que nuestra hipótesis funcione en el mercado. En otras palabras, pondremos a prueba nuestra idea. La manera más obvia y sencilla de probar nuestra hipótesis es ver si arroja resultados positivos.
-
Evaluación de la hipótesis: este es el proceso por el cuál intentaremos comprender si los resultados arrojados por la estrategia son coherentes con nuestra idea inicial. El objetivo es poder verificar que la lógica de nuestra premisa es sólida y es el motivo por el que arroja los resultados obtenidos. Puesto en un ejemplo, si nuestra premisa es la de una estrategia intradiaria, querríamos ver que los beneficios vienen de trades de corta duración y no de una o dos operaciones que hayan capturado una tendencia de largo plazo.
-
Optimización de variables: aunque personalmente intento evitar optimizar cualquier estrategia (o hacerlo lo mínimo posible), soy consciente de que muchos otros traders sí utilizan este proceso con éxito. En cualquier caso, la optimización de variables deberás hacerla siempre en el periodo IS. Esta optimización se basará en buscar los valores de parámetros (por ejemplo, el periodo de una media móvil) que mejor haya funcionado en el pasado, esperando que siga siendo así en el futuro (algo improbable).
Caducidad de los datos IS
Teóricamente, podrías utilizar los datos IS tantas veces como quisieras, pero deberás hacerlo con cautela ya que esto implica varios peligros. La razón es que cada vez que introduces una nueva regla y haces una prueba en los datos IS, si obtienes mejores resultados y te quedas con esa nueva regla, lo que has hecho realmente es optimizar el backtest.
Aunque esto parezca inofensivo, a cada nueva regla o a cada nueva iteración que mejore los resultados, lo que está ocurriendo es que el modelo captura mejor las idiosincrasias y/o el ruido de los datos históricos, pero nada garantiza que el futuro sea como el pasado.
Además, como más reglas pruebes en un mismo set de datos IS, mayor probabilidad existirá de que encuentres un falso positivo entre ellas. Es decir, una regla que parece arrojar resultados positivos, pero que ha sido, simplemente, fruto de la suerte.
Evidentemente, esperamos que el futuro sea parecido al pasado, por eso nos fiamos del backtest, pero nunca va a ser exactamente igual. Y como más reglas y condiciones le añadamos a nuestras estrategias, más vamos a necesitar que el futuro se parezca al pasado para poder sacar rendimientos.
Cuanto más sencillas y genéricas sean las reglas de tu estrategia, mejor se adaptarán a futuros precios.
Los peligros de las máquinas del tiempo
Quiero aprovechar la ocasión para hablarte del concepto de la “máquina del tiempo”. Aunque suene divertido, debemos ser conscientes que probar estrategias con datos históricos implica que podemos cometer el error de tomar decisiones o dar ciertos resultados por buenos que, en circunstancias normales, hubieran sido imposibles de obtener. Deja que me explique.
Por ejemplo, si has realizado un proceso de optimización de una estrategia y estás satisfecho con los resultados que arroja durante los datos IS, deberás ser consciente de que para obtener esos resultados has utilizado una “máquina del tiempo”. Esto es así debido a que los valores del proceso de optimización han tenido en cuenta el desempeño de la estrategia en, por ejemplo, el año 2012, pero el inicio del periodo es el 2008. Como comprenderás, en el año 2008 no hubieras podido acceder a los datos del 2012, por lo que los resultados del backtest no serían algo que hubieras podido conseguir.
Por esta razón, deberás ser pesimista en cuanto a los resultados del periodo IS y, si has realizado alguna optimización, no tener los resultados en cuenta a la hora de calcular métricas de rendimiento, ya que serán artificialmente altas y no fieles a la realdidad.
Dicho todo esto, una vez estés satisfecho con los resultados que arroja tu modelo, será el momento de comprobarlo en los datos OOS, de los que sí podrás sacar conclusiones robustas.
Datos Out-Of-Sample (OOS)
Por otro lado, en el rango de datos OOS (fuera de muestra) harás la validación de la estrategia. Este es, en esencia, un paso tan sencillo como fundamental.
El único objetivo es comprobar que el rendimiento que la estrategia tenía en los datos IS se mantiene durante los OOS, que son unos datos que la estrategia no había visto nunca antes.
Los datos fuera de muestra nos ayudan a emular lo que la estrategia se encontraría a tiempo real: datos nuevos.
Validación fuera de muestra
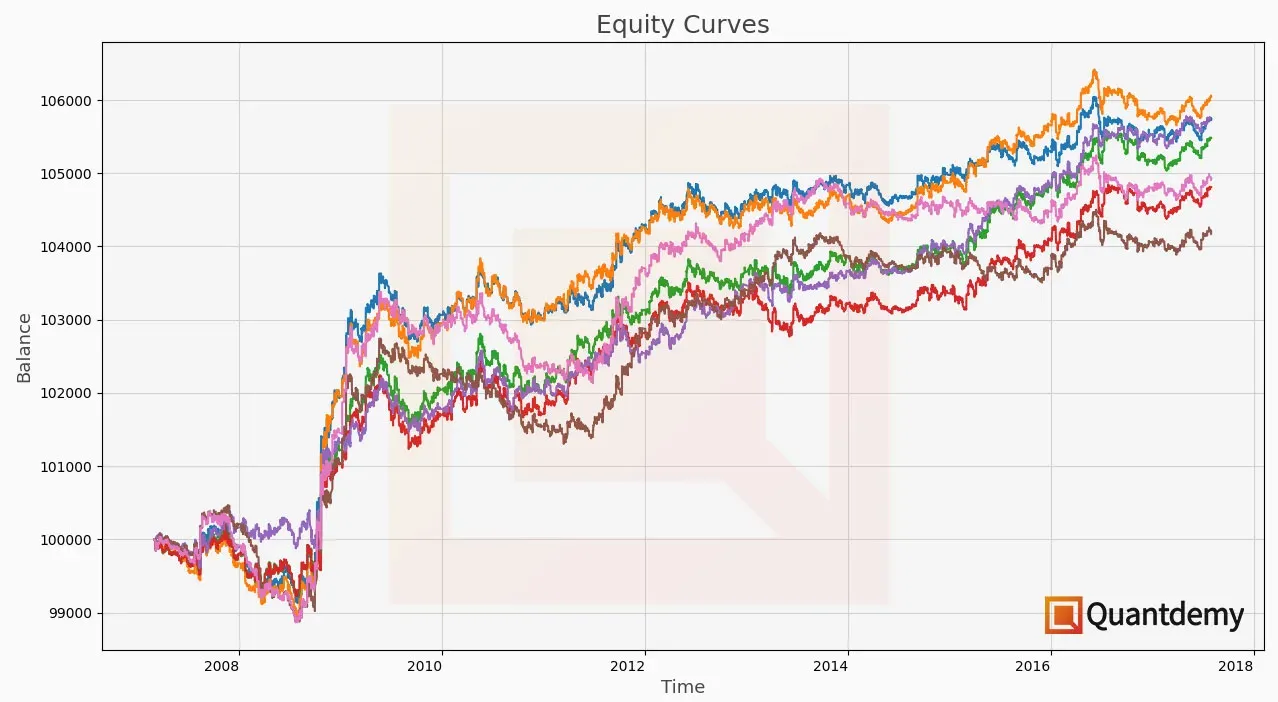
Este punto es extremadamente importante ya que es donde deberás evaluar si tu estrategia ha sido sobreoptimizada, un problema potencialmente peligroso que quizás conoces también bajo el nombre de overfitting o data-snooping. Este es un tema que trataremos en profundidad en próximos artículos.
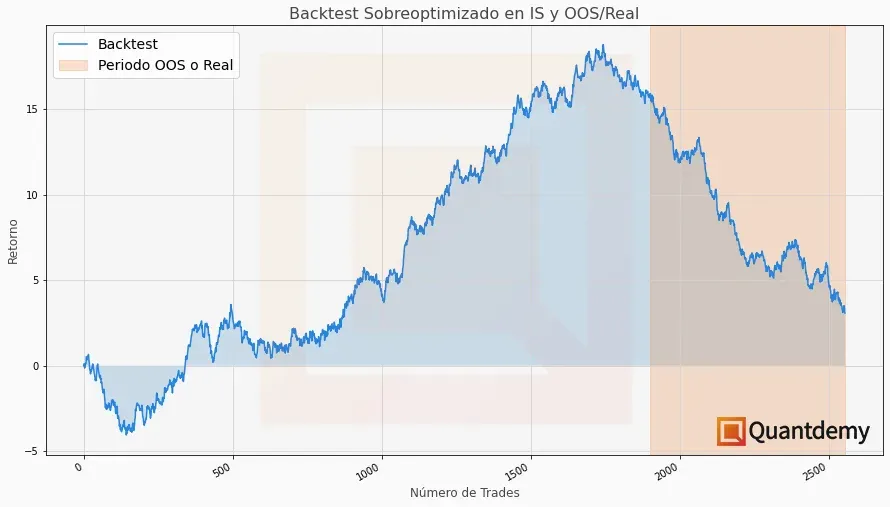
¿Te suena el escenario de la imagen de arriba? Creo que, siendo sinceros, a todos nos ha pasado (o al menos a mi en varias ocasiones, sobretodo en mis inicios) que la curva que obtenemos del backtest es estable, siempre creciente, y prácticamente perfecta. Sin embargo, cuando hacemos la validación de la estrategia en los datos OOS (o peor aún, llevamos la estrategia a operar con dinero real directamente) obtenemos unos rendimientos que nada tienen que ver con lo que mostraba el backtest. Este es un síntoma inequívoco de que nuestra estrategia estaba sobreoptimizada, y por eso es tan importante la prueba con los datos OOS.
Nuestra estrategia estaba construida para funcionar perfectamente en los datos del pasado, pero sus normas no eran lo suficientemente generales como para poder seguir ganando en datos no vistos hasta ahora.
Si una misma estrategia es ganadora en el periodo IS pero es notablemente perdedora en el OOS y puedes ver claramente y a simple vista el punto de inflexión de un rango de datos a otro, y éste coincide con el inicio de los datos OOS, no deberías poner la estrategia a trabajar con capital real.
Uso responsable del periodo OOS
Como puedes ver, utilizar la metodología de dividir tus datos en periodos IS y OOS es un paso indispensable en el proceso de prueba de tus estrategias de trading algorítmico. Piensa en la verificación OOS como un cortafuegos que no dejará que las estrategias perdedoras lleguen a ejecutarse en real, ahorrándote así una considerable suma de dinero a lo largo de tu carrera y muchos dolores de cabeza.
Desafortunadamente es muy complicado poder asegurar que la estrategia está libre al 100% de este problema (sobreoptimización), ya que los resultados podrían ser, sencillamente, fruto de la suerte. Por este motivo es tan importante realizar la verificación del sistema de trading utilizando los datos OOS. Si la estrategia está libre de overfitting, verás que se comporta de una manera similar a la que lo hacía en los datos IS. Esto reduce considerablemente la probabilidad de sufrir de sobreoptimización y es una primera muestra de robustez.
Otro punto de extrema importancia es que si la estrategia arroja buenos resultados durante el periodo IS pero no en el OOS, no toques sus parámetros para hacer que también arroje buenos resultados en el periodo OOS. Si lo hicieras, estarías optimizándola de nuevo y habrías convertido los datos OOS en parte de los IS, manipulando los resultados y eliminando su validez. En otras palabras:
Solo tienes una oportunidad para probar la estrategia en los datos OOS y mantener su integridad.
Pero no está todo perdido. Si desconocías esta metodología y ya has consumido tus datos OOS, aún te queda otra baza: poner la estrategia a operar en el mercado a tiempo real con una cuenta demo (con dinero ficticio). Este proceso no será tan rápido como el backtest, pero te asegurará que los resultados sean 100% fuera de muestra. Este procedimiento también es conocido como incubación, y es algo a lo que volveremos en otro artículo futuro.
Conclusión
Espero que, con este artículo, hayas podido entender por qué es tan importante el proceso de separar los datos en los rangos en muestra y fuera de muestra para mantener la integridad de los resultados de nuestro backtest.
Al fin y al cabo, lo que queremos es que el backtest sea lo más fiel a la realidad posible para que represente de manera fidedigna lo que podría ocurrir en el futuro. De nada nos sirve forzar el backtest para que nos muestre los resultados que queremos ver, si luego vamos a perder dinero operando en el mercado real.
Como siempre, si tienes alguna duda puedes contactar con nosotros a través de nuestra comunidad en Discord.
Muchas gracias por tu lectura y nos vemos en el siguiente.
Martí


